In academics, nothing seems more helpful for the students, researchers, and faculty members to get enough information for research than Google Scholar. Various features make this search engine handier and really lifesavers, such as its academic literature, forward citations, and auto-generated Bib TeX.
At times, when you need a big chunk of data from Google Scholar, you can’t do that due to some of its restrictions. So, you can use web scraping to extract the content from Google Scholar to search a bulk of scholarly articles and various academic resources.
If you are eager to get them, stick to this guide. It will pave the way for you to scrape Google Scholar data in a more convenient methodology.
Can You Scrape Google Scholar
Yes, Google Scholar can be scraped easily. Although it seems somewhat tricky, it can be done if you get a reliable Google Scholar scraper to extract the academic literature with no hassle.
However, you should pay attention to your local laws about data scraping. And the copyright or privacy of using these data.
What data can be extracted from Google Scholar
You can fetch huge data from Google Scholar, including research papers, and automatically build a database of forward & backward citations, and various academic resources, i.e., ResearchGate, academic social networking sites, and more.
Is there an API for Google Scholar
Google Scholar does not provide official API access for web scraping. The robot.txt of this search engine forbids web scrapers from scraping most pages. It is supposed to be accessed by its bots or some third-party APIs and impermissible for this action. However, you will get a CAPTCHA to clear out if you request to reach on such certain information.
How to Scrape Google Scholar Without Coding
To scrape Google Scholar data, there is an immense need to learn difficult coding languages. However, you can use Octoparse, which can help you scrape Google Scholar data into Excel without coding. Octoparse can scrape the web page automatically, and you can apply advanced functions like pagination, loop, Ajax timeout, etc.
Octoparse also provides a preset template for scraping Google Scholar articles information that can be used directly to extract the whole data. And what you need to do is entering the keywords and wait for the results. Find it from the Template panel of Octoparse, and you can preview the data example.
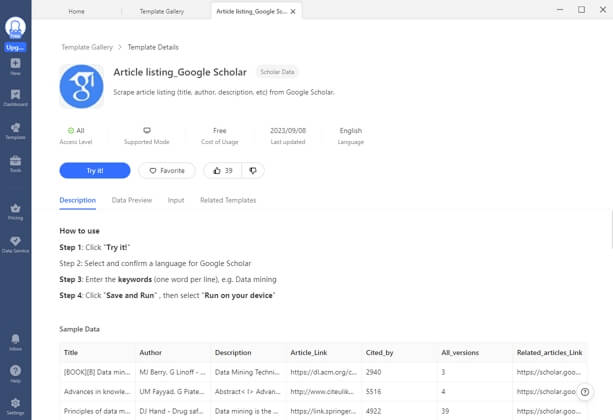
3 steps to scrape academic resources from Google Scholar
Download Octoparse and install it on your device, and sign up an account for free. Then, follow the simple steps below or reading the detailed user guide about scraping Google Scholar data. You can also watch the video here to help you understand more.
Step 1: Enter the page link you need to scrape from Google Scholar
First, go to the target page of Google Scholar, copy the URL, and enter it into the Octoparse search bar on the home screen. Then the targeted URL will be scraped automatically after you click on the Start button.
Step 2: Customize the workflow to get more data
After the auto-detection process, a workflow will be generated. You can make changes with the Tip panel to get more data. The preview section will show what will be scraped.
Step 3: Extract data from Google Scholar search result page
Click on the Run button to start scraping and wait a few moments. Finally, you can download the scraped data in an Excel/CSV file or save it to your database directly.
You can also scrape the search results from Google or Bing directly if you want to find more information, which can’t be found from Google Scholar.
Scrape Google Scholar Using Python
In the current scenario, one has to learn programming languages to scrape Google Scholar data. Although, an easy-to-go method has been discussed above. However, you must also learn how to extract Google Scholar data with Python. So, learn it in a few simple steps.
Step 1: Firstly, prepare virtual environment and install libraries for CSS selectors to extract data from relevant tags and attributes.
Step 2: Add the SelectorGadget Extensionsto grab data from CSS selectors. Then use the specific Python codes to scrape Google Scholar organic search results.
Step 3: Use SerpAPI for this, as it can extract title, snippet, publication information, link to an article, link to related articles, link to different versions of articles, and links at the bottom; BibTeX, EndNote, RefMan, RefWorks, etc.
Step 4: Apart from this, SerpAPI can also scrape Google Scholar Profiles info, including author name, link, affiliation(s), email, interests, cited by, and Public access.
Step 5: Next another important data is Google Scholar cite results. For this, a temporary list is created to store citation data. Use these command lines to iterate over organic results and pass the results id to search query:
os.getenv (“API_KEY”), “engine”: “google_scholar_cite”, “q”:
Citation [“result_id”] } search = GoogleSearch (params) # from where extraction happens on the backend
results = search.get_dict () # from where JSON string is coming from
Step 6: Then you have to pass a returned list of data from organic and cite results to Data Framedata argument and let it save to CSV.
Step 7: Some particular commands you can use as per your desire, either delete or add any column from selected data.
# delete all data from the whole table
conn.execute ( “DELETE FROM google_scholar_organic_results” )
# delete table
conn.execute ( “DROP FROM google_scholar_organic_results” )
# delete column
conn.execute ( “ALTER TABLE google_scholar_organic_results DROP COLUMN authors” )
# add column
conn.execute ( “ALTER TABLE google_scholar_organic_results ADD COLUMN snippet text” )Thus, the Python coding will scrape Google Scholar data.
Final Thoughts
If your academic life is going on, you would be using Google Scholar to get the latest and old scholarly articles and various other academic resources, including forwarding citations. Google Scholar web scraping can add more value to your academic journey. Just use Octoparse to help you extract a bulk of data from web pages to your own local devices. You have no need to learn strenuous programming languages.