This article will offer a full guide to scrape Yelp data easily without any coding skills required. If you want to bulk download datasets from Yelp (including business data, contact numbers, websites, reviews data, etc.), this is a good one to try.
Yelp Web Scraping
Talking about Yelp scraping, you might be interested in this – among the list of most scraped websites, Yelp ranked as the top 4 most scraped by Octoparse users. Most of them try to gather local business data such as the business name, contact number, address, timetable. Many are also collecting reviews from the customers.
As a local business aggregator and customer review platform, Yelp is helpful if you want to:
- Generate a list of local business leads for various industries
- Learn how your competitors are doing and what they are offering
- Do research on a specific industry
Whatever Yelp data you are looking for, as long as it is visible on the web page, it is available for web scraping. So let’s cut to the chase, how to scrape Yelp data?
3 Easy Methods on How to Scrape Yelp Data
Here, we’ll introduce Octoparse, the web scraping tool designed for non-coders. We will show you how to get your own Yelp scraper (maybe your first web scraper) in just 5 minutes.
There are 3 ways to scrape Yelp data with Octoparse, the one is building a crawler for free, and the other two are using pre-built Yelp scraping templates that are built by our developers, uploaded to our software, and ready-to-use right away. You can choose any of methods as your needs.
Before getting started, you need to download and install Octoparse on your Mac or Windows device, and sign up for a free account.
Method 1: Build A Crawler to Get Data from Yelp
This method helps you scrape any public data from Yelp including the ratings, customer reviews, locations, etc. You can set pagination and loop item to customize your scraping process. Follow the simple steps below to scrape Yelp data with Octoparse.
Step 1: Copy the Yelp page link you need to scrape, and paste it into Octoparse. You’ll enter the quick auto-detecting mode by default.
Step 2: Create a workflow and customize the data field by clicking or using simple Xpath. Make sure you have all the data in the Preview mode.
Step 3: Run the Yelp crawler, the process will be finished very soon. Download the scraped file in Excel, CSV, or other formats to your local devices.
Check out the video guide of Octoparse Yelp scraper
Method 2: Scrape Yelp Business Data by Location & Category
Though I kind of have already revealed that Octoparse offers pre-built scrapers for Yelp, yet even for any other websites, you can always try searching the website name in the software and it will tell you right away if any templates are available.
Step One: Find the Yelp scraper (Keyword Search Result Yelp (Python))
Search “Yelp” in Octoparse and we will see a template named “Keyword Search Result Yelp (Python)” and other Yelp scrapers-choose the one you want to use. “Keyword Search Result Yelp (Python)” is the one we are going to use here.
When you click into the template scraper, you will see a short guideline explaining what this specific template does, how to use it (description), what kind of parameters you shall enter (parameters) and what data you can get (data preview & sample).
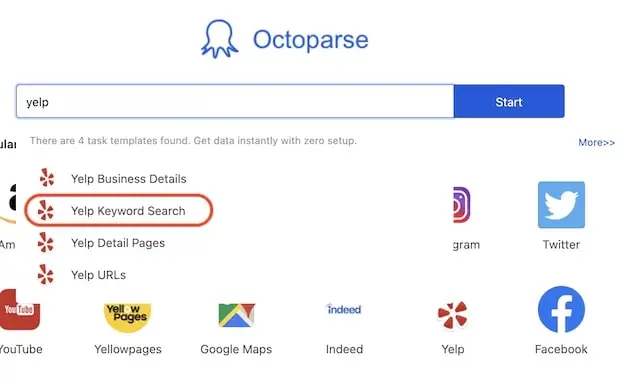
It’s ok if you don’t want to read it all. Just click the little blue “Try it” button above to start setting up the scraper.
Step Two: Enter the parameters into your scraper
Now you are the commander to tell what your Yelp scraper shall do for you. There are three blanks you need to fill here:
- Locations – The location want like to search nearby, ie. New York
- keywords – What type of business data do you want to scrape, ie. restaurants or more specific: pizza
- PageSize – How many pages of data do you need to scrape
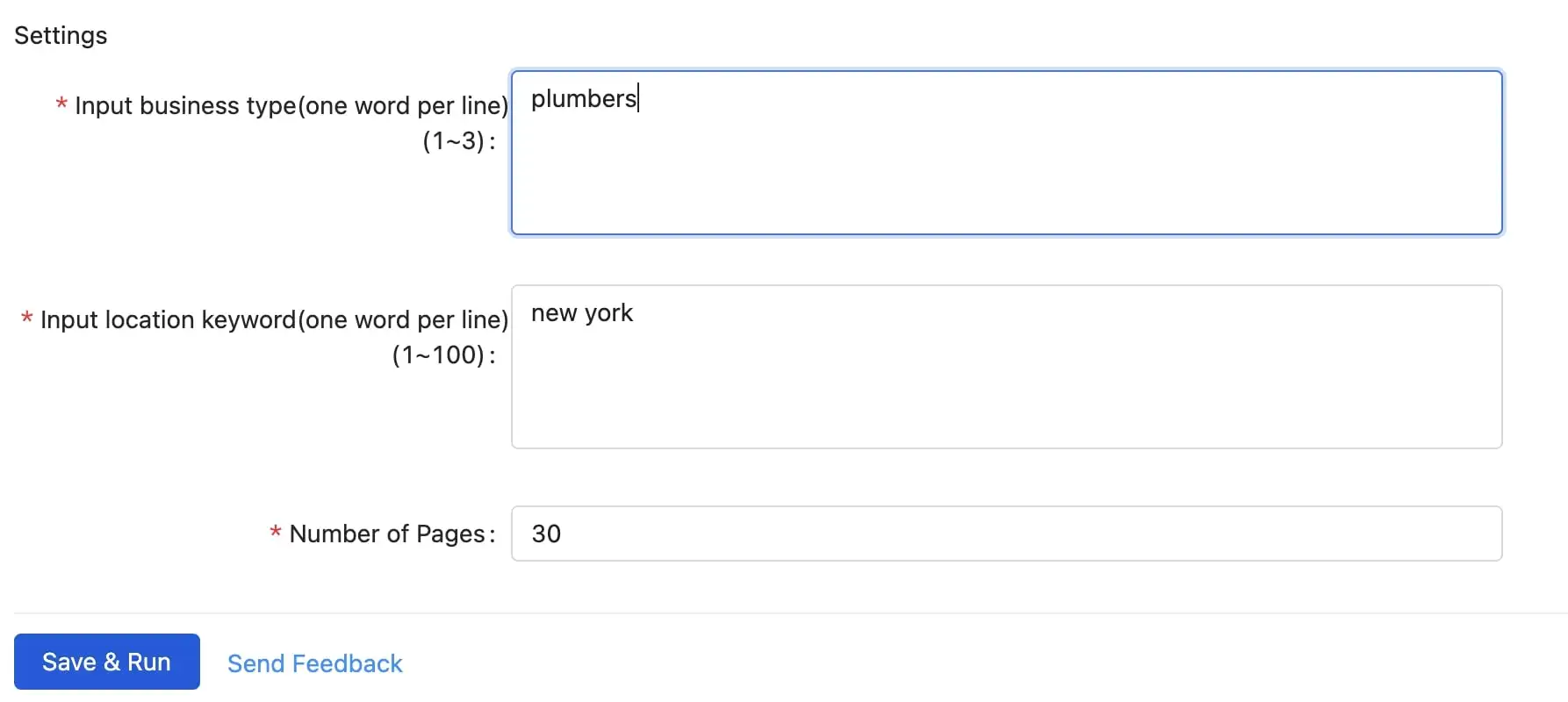
While you are filling in the blanks, here are a few things to watch out for:
- Enter business types one word per line. You can enter up to 10 keywords. Don’t keep an empty line in the textbox or it will be counted as a parameter too.
- Enter location keywords one word per line. You can enter up to 10 keywords.
- Enter the number of pages you want to scrape. Keep in mind that the maximum number of pages Yelp shows publicly is 24.
Step Three: Run the scraper and export the data when it is completed
This particular Yelp template can only be run in the Cloud (so that the scraper can manage to scrape with IP rotation to avoid blocking), you need to subscribe to Octoparse and unlock the Cloud services.
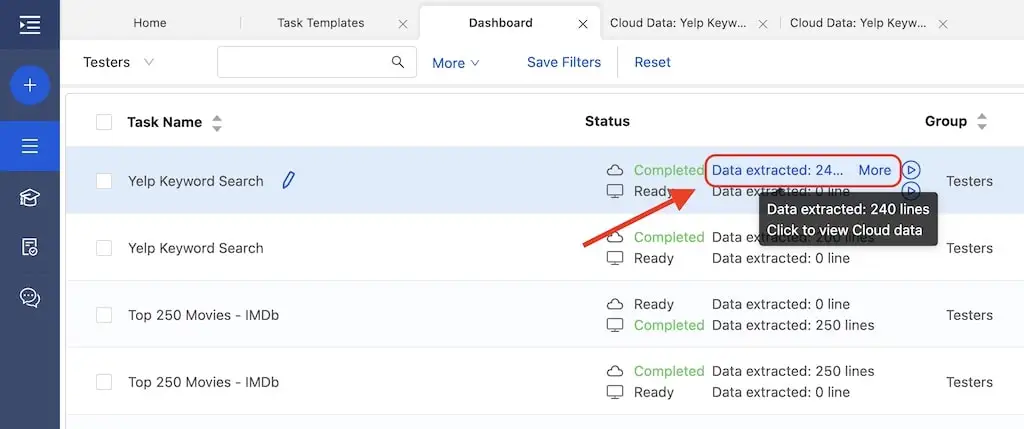
If you haven’t done so already, click the “Save & Run” button to run the scraper in the Cloud, and the scraper will work diligently for you to get the yelp data downloaded.
On the “Dashboard” you will find all the scrapers (tasks) you have built and see if the task’s been completed. The task we built should be named “Keyword Search Result Yelp (Python)” (same as the name of the template) by default. Click to view the data, and this is what it looks like:
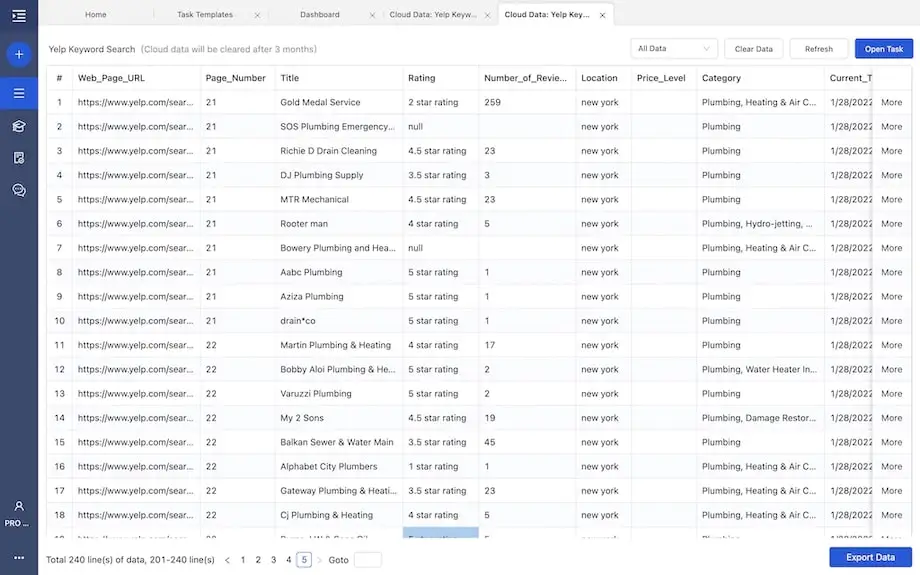
You will be able to export the extracted data to all kinds of formats like Excel, CSV, JSON, and HTML. Alternatively, you can also export the data to your database or data visualization tools via Octoparse APIs.
Tips: The website may secretly change its structure from time to time which may affect the data results obtained by the scraper. Send us feedback if you find the template is not making you happy. We are happy to help update it as soon as possible.
Method 3: Scrape Yelp Business Data by Detail Pages
The process is very much like what we have gone through above. The steps are almost the same, only we are gonna use a different template. So I won’t go into as much detail as the above. Don’t sweat. The below guideline is more than enough to walk you through.
- Step One: Find the Yelp scraper (the template named “Detail Pages URL Yelp”)
- Step Two: Enter the parameters into your scraper
- Step Three: Run the scraper and export the data when it is completed
The only difference here is the parameter you’ll enter into the blanks. This time, enter the URLs of the actual search results you wanna scrape data from. You can enter one or more URL’s depending on your specific requirements. For example, https://www.yelp.com/search?find_desc=plumbing&find_loc=San+Francisco%2C+CA is the URL of the search results page I get when I search for plumbing services in San Francisco.
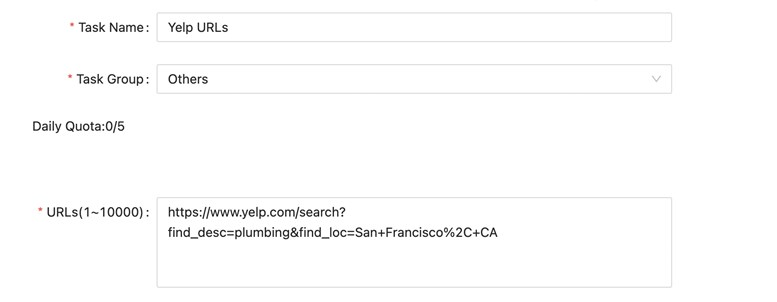
Then you should get similar structured data as before. If you haven’t got your feet wet and built yourself a Yelp scraper, try it out!
Scraping Food Delivery Apps
Food delivery services have grown fast (with cut-throat competition), especially since the 2020 pandemic. The lockdown or social distancing somewhat changed a part of people’s lifestyles. Food delivery app data is also hot in recent days. When you get a hang of Octoparse, you can scrape data from websites like Grubhub, Doordash, and Uber Eats with the same steps in Method 1.
Learning a new thing from scratch always requires a leap of faith – to convince ourselves that we can do it, and it is not as difficult as expected. Well, isn’t this what life is all about – keep trying new things and not get defeated.
That’s why we’ve been working hard to create a no-code web scraping tool for everyone who wants to make the most out of web data. Gone are days when web scraping was strictly for programmers. All Octoparse does is bringing you the smoothest and most reliable scraping experience.




