Data Science and Analysis is becoming increasingly important, as people are drowning in the oceans of information. The data scraped from websites can be used in many industry fields, like business, scientific analysis and others. And we can use the scraped data to process with more deep learning, like data purge, machine learning, sentiment analysis, prediction and etc. Thus, the notion of scraping data shouldn’t be a new term to anyone. Data Scraping (web harvesting or web data extraction) is meant for extracting data from websites.
There are several existing methods to scrape data that people mostly adopt. First, as we know, there are many website providing public APIs for users to access to their dataset, like Facebook, Twitter, and etc. People with data needs can refer to these APIs and check if the data fields they provide could meet their data requirements. However, these data can’t satisfy people’s needs sometime. In this case, users need to build their crawlers on their own by programming or using other automated scraper tools to crawl more data. Usually, people can scrape websites using Ruby or Python. However, this method itself sets a quite higher entry for many people without coding skills, and the coding process and related configurations also will cost some time for most people.
Thus, many people with data scraping requirements prefer using data scraper tools which can scrape data they need automatically. More specific, a web scraper we used to scrape data from websites (also known as a web spider or web robot) is a program or automated script which crawl the World Wide Web in a automated and structured way. There are many scraper tools you can find when you search Google. Here, I just want to share with you how I start up scraping data using a specific scraper tool – Octoparse and how it works to scrape the target website. Anyway, what I propose is just based on my user experience, you still should be careful with the service provider you subscribed to based on your own requirements.
Octoparse is a Windows desk-top scraper tool which keeps commiting itself in providing high-quality scraping service. It’s noteworthy that Octoparse provides two editions of their service basically – the Free Edtion and Paid edition. If users would like more advanced service, like Cloud-based service and faster scraping speed, they can switch their free account to any paid acount within which the Cloud Service is available. Anyway, both editions can provide users with the basic elegant scraping service to scrape data from websites and have crawled data results exported to various formats. To start your scraping task, you should visit their official website, download it and have it installed on your local machine. The UI of Octoparse is user-friendly, you can see the figure as below. You need click Start of Advanced Mode to begin configuring the basic information of your task.
Then, Click the Next button to proceed with your task. As can be seen in the example figure below.
Then, enter the URL of the target website in the web browser and click Go.
Then, you can right click the Next button and select the Loop click Next Page button so that you can scrape data page after page in a loop.
Next, right click the data object you would like to scrape data from and add them to the list.
By click and select, you can choose the data fields you’d like to scrape, as the following shows.
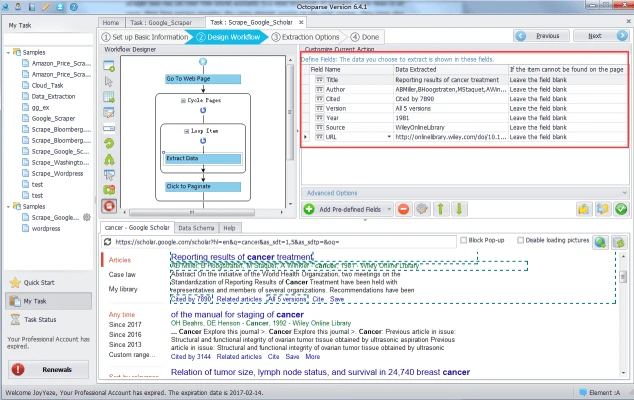
(This is the old Octoparse 6 UI. You may find surprises with our brand new Octoparse 8)
Then, after several steps of configuration, you can save your task and proceed with local or clould extraction. Then the data will be returned as below.
What I share above is just some of my user experience, if you’d like to learn more about how to use this tool. Just visit Octoparse official website where more detailed tutorials will be available.