A web crawler, also known as a web spider or search engine bot, is a bot that visits and indexes the content of web pages all over the Internet. With such an enormous amount of information, a search engine will be able to present its users’ relevant information in the search results.
What is a Web Crawler?
The goal of a web crawler is to get information, often keep getting fresh information to fuel a search engine.
If a search engine is a supermarket, what a web crawler does is like grand sourcing – it visits different websites/web pages, browses, and has the information stored in its own warehouse. When a customer comes over and asks for something, there will be certain goods to offer on the shelves.
It sources by indexing web pages and the content they contain. The indexed content will be ready for retrieval and when a user searches for a particular query, it will be able to present the user with the most relevant information.
A web crawler is a super workaholic or it must be one. This is not only because there is an enormous number of new pages being created every minute in the world (around 252,000 new websites are created every day worldwide according to Siteefy), but also due to the changes and updates of these pages.
There are some web crawlers active on the Internet:
- Googlebot
- Bingbot
- Yandexbot
- Alexabot
They are mainly for search engines. Despite web crawling bots that work for a search engine, some web crawlers gather website information for SEO purposes, such as site audit and traffic analysis. Instead of offering search results for search engine users, they give valuable information to website owners (like Alexa).
How to Do Web Crawlers Work?
Since you have a basic idea about what a web crawler is, you may wonder how a web crawler works.
There are a vast number of web pages available on the Internet and the number is growing fast every day. How does a web crawler go over all of them?
In fact, not all content on the Internet is indexed by web crawlers. Some pages are not open to search engine bots(#) and some just don’t have the opportunity to meet any of them.
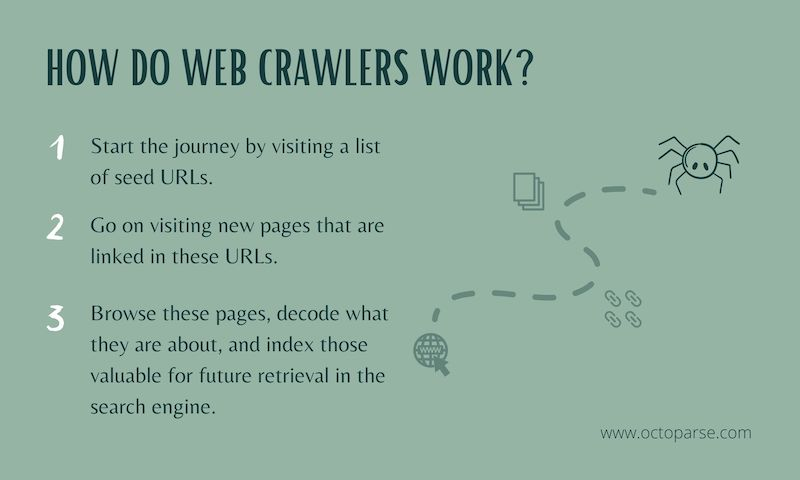
Start from Seed URLs
Normally, a web crawler bot starts its journey from a set of known URLs, or what is called seed URLs. It browses the meta information of web pages (for example title, description) and also the body of the web page. As these pages are indexed, the crawler keeps going through the hyperlinks to visit web pages that are linked to the seed pages.
Hence, this is the basic route that a web crawler would take:
- Go to the list of known web pages
- Extract the URLs that are linked in these web pages and add them to the list
- Continue to visit the newly added pages
By visiting web pages constantly, web crawlers can discover new pages or URLs, update changes to existing pages, as well as mark those dead links.
Web Crawlers Prioritize
Even though web crawlers are automated programs, they cannot keep pace with the fast expansion of the Internet and the constant changes in web pages. In order to capture the most relevant and valuable information, web crawlers have to follow certain rules that help prioritize all the added links, to visit first.
For example:
- Web pages that are linked by many other relevant pages will be thought more informative than those pages without any referral. Web crawlers are more likely to prioritize the visit to these web pages.
- Web crawlers revisit web pages to make sure they follow up on the updates and get fresh information. A web page that updates regularly may be crawled more frequently than those that seldom make any changes.
All these rules are made to help this whole process be more efficient and be more selected on the content they crawl. The goal is to deliver the best search results for search engine users.
About Indexing
A search index helps a search engine return results fast and efficiently. It works like an index in a book – to help you get to the needed pages (information) fast with a list of keywords (or chapters).
The crawler builds the index. It visits the pages of the website, collects the contents, puts them into an index, and sends them to the database. You can take the index as a huge database of words and corresponding pages where they appear.
For webmasters, making sure the website gets indexed properly is important. Only when the web page is indexed will it show in the search results and be discovered by the audience. While a website owner can decide how a search robot crawls its website as well. Robots.txt is such a file webmasters create to instruct search robots on how to crawl their pages.
How Does Web Crawling Affect SEO
As we have mentioned, how a search robot crawls your website may affect how your pages are indexed and hence whether it is shown in the search results. This is obviously what an SEO professional would care about.
If the ultimate goal is to get more traffic from a search engine like Google, there are a few steps you should pay attention to:
Get Crawled: High-quality Backlinks
A web crawling bot starts from a list of seed URLs and they are normally quality pages from high-authority websites. If the page you want to rank is linked by these pages, it will definitely be crawled by the bot. We do not know what the seed URLs are, but you are more likely to get crawled if you have more backlinks, especially when they come from good-performing websites.
In short, it is essential to earn more external links to your website, especially from high-quality, relevant pages.
Get Indexed: Original Content
Your page can be crawled but not indexed. Web crawling bot is selective. It won’t store everything they have seen in the index for search. There is a way to find out how many pages of your website are indexed by Google – input “site: your domain” and search on Google.
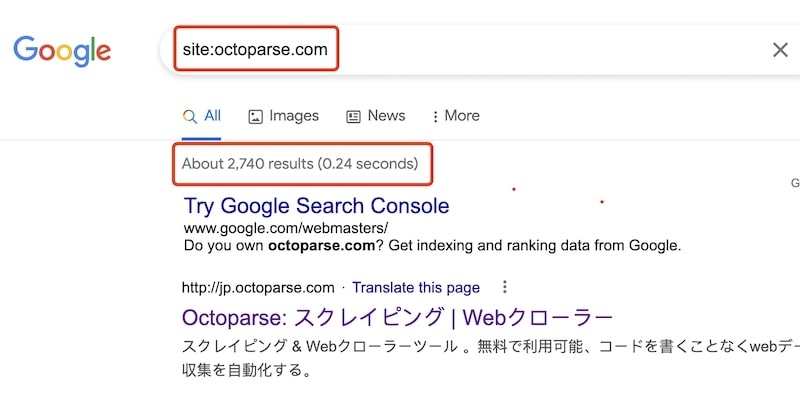
If you want to know exactly what pages are indexed and what are not, the data is available on Google Search Console: Google Search Console < Index < Coverage
So what kind of content gets indexed (by Google for example)? There are many influential factors taking place and what comes first is to write original content. Google’s mission is to offer valuable content to its users. This is almost the same for all search engines and duplicate content is always the target for punishment. Do search intent and keyword research. Write and tell your own story or opinion.
Differences Between Web Crawling And Web Scraping
Sometimes, web crawling and web scraping are used interchangeably. However, they are applied in very different scenarios for different purposes. Web crawling is about a search engine bot exploring unknown pages to store and index, while web scraping is to target a certain list of URLs or domains and extract needed data into files for further use.

Web scraping and web crawling work differently.
As we have discussed above, web crawling starts from a list of seed URLs and keeps visiting what is linked to extending the reach to more unknown pages. Even though a crawling bot might have a set of rules to decide which page to visit before others, it does not have a fixed list of URLs or is confined to a certain kind of content.
However, web scraping has its clear target. (What is web scraping?) People come to web scraping with a list of URLs or domains and know exactly what data they are capturing from these pages.
For example, a shoe seller may want to download shoe suppliers’ information from Aliexpress, including the supplier’s name, product specifications, and prices. A web scraper will visit the domain (Aliexpress), search a keyword to get a list of relevant URLs, visit these pages and locate the needed data on the HTML file and save them to a document.
They have different purposes.
Web crawling is to explore and scrutinize as many pages as possible, index those helpful, and store them in the database in order to build an efficient search engine.
A web scraper can work for very different purposes. People may use it to gather information for research, data for migration from one platform to another, prices for competitor analysis, contacts for lead generation, etc.
They have one thing in common – they both rely on an automated program to make the work (impossible for a human) attainable.
For More on Web Scraping
If you are interested in web scraping and data extraction, there are a few ways to get started.
Learn a programming language.
Python is widely used in web scraping. One of the reasons is that open-sourced libraries like Scrapy and BeautifulSoup are well-built and mature to run on Python. Besides Python, other programming languages are used for web scraping as well – such as Node.js, Php, and C++.
Learning a language from scratch takes time and it is good if you can start from what you are familiar with. If you are a newbie, better evaluate your web scraping project and choose a language that best fits your demand.
Kick starts with a no-code or low-code web scraping tool.
It takes really some time and energy to learn a programming language from scratch and be good enough to cope with a web scraping project. For a company or entrepreneurs who are busy maintaining a business, data services or a low-code web scraping tool is a better option.
The primary reason is that it saves time. Since Octoparse launched in 2016, millions of users have used Octoparse to extract web data. They take advantage of the interactive workflow and intuitive tips guide to build their own scrapers. A low-code tool also empowers team coordination as it lowers the threshold to deal with web scraping and web data.
If you need to download web data, try Octoparse (free plan available). These webinars will get you on board and more importantly, if you are stuck, please feel free to contact our support team (support@octoparse.com). They will have you covered.