Having good knowledge about a business domain is key for businesses to be aligned with their competitors. But, news reading, collection, and getting enough News knowledge is a hectic job and takes a lot of time. So, scraping News Sites is a must for fast and quick knowledge gain in the news industry.
Scraping news sites helps you to get key and important updates and news about a business in a very short time. This article explains everything you need to know about news scraping, and how to scrape news sites easily and quickly.
Why News Web Scraping
In this section, we’ll discuss key stuff about News Sites Scraping. Let’s have a look.
What is news scraping
News Scraping is a specific term being used for scraping only news websites by getting data from public online media websites. It means extracting updates and press releases automatically from news websites. Extraction of public data available on News Sites is allowed.
It’s good for businesses to extract data from news sites as these websites contain a lot of crucial public data, many public reviews about newly launched products, and many other keys and necessary announcements for businesses.
Learn the example of how to scrape news articles from Bloomberg easily.
Is it legal to scrape data from news sites
Yes, it is legal to scrape public and openly available data from News websites. Scraping any website for public data is legal but you should know about local laws and regulations to get updated about the legal aspects of News Sites Scraping.
Some data available on News Sites can be private and not allowed to be scrapped because it has been restricted by the world’s authorities for data regulation.
Benefits of news sites scraping
Scraping data from News Sites is too much beneficial and plays key roles in:
- Enhances compliance and Operations.
- Gives up-to-date information about business updates and many more.
- Information on News Sites is verified and authentic.
- It helps to identify mitigation and risks.
- Plays important role in giving information about key business announcements.
How to Scrape News from Any Sites Without Coding
If you don’t have enough technical knowledge about website scraping and python programming language, don’t need to be worried, as Octoparse is here to help you every time. Octoparse is an amazing and powerful web scraping tool with thousands of features. It allows you to scrape News from any site within no time, even without knowing python programming and technical skills.
Octoparse is available in free as well as premium versions with a lot of features. It is a powerful tool with the power of scraping multiple News Sites in just a few seconds. Now, how to use it for website scraping?
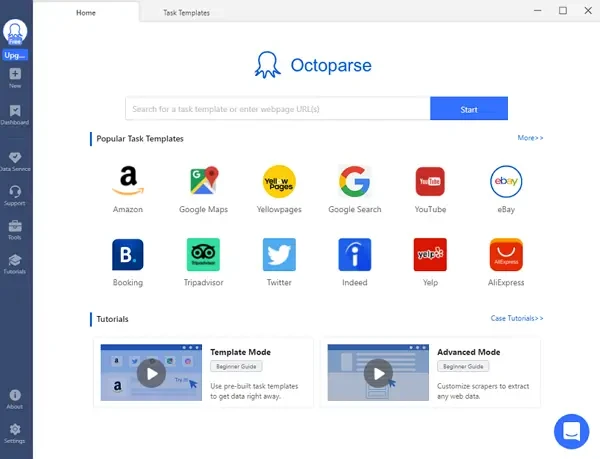
Steps to scrape news with Octoparse
Step 1: Enter page link copied from News site
First, go to Octoparse official website, download and install it in seconds. Copy the news site page link you want to scrape, and paste it into the search bar of Octoparse. Click on the Start button to enter the auto-detecting mode.
Step 2: Create a workflow for News data
After the auto-detection completes to 100%, you can create a workflow and make changes by adding loops like scrolling page loop and clicking on each item loop.
Step 3: Extract data from News site
Check all your data in the preview section. Click on the Run button to start scraping news, and export it in Excel to your local device.
Scraping News Articles with Python
There are a lot of packages available in python to scrape information from News sites. One of the known packages is BeautifulSoup. BeautifulSoup helps to parse the HTML code of a given link and access its elements by finding them with their attributes i.e. tags. Due to this reason, we use it to scrape data from news sites.
To install BeautifulSoup, add this code to your python distribution.
! pip install beautifulsoup4
To provide BeautifulSoup with the HTML code for any page, you need to add a “Request Module”. You can add requests as:
! pip install requests
Two commands will be needed to scrape data from news sites.
First, find_all(element tag, attribute, it will help you with locating any HTML elements from a News Site by identification of tags and attributes. This command will help you out with getting all elements of the same type. To get the first one, you have to use find().
Second, get_text(), once you are done, this command will help you with the inside text.
News scraping is a way to get a lot of information about top stories going on in the world without digging too deep. Octoparse is an amazing tool to get scraped data from News Sites in seconds without being blocked and restricted. So, what are you thinking about? Just download Octoparse software and start scraping news websites.